Unicode
1 min read
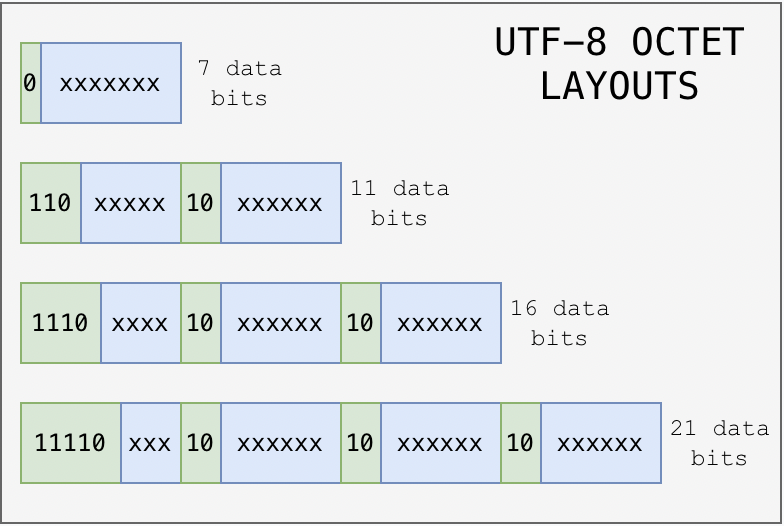
- If the character can be expressed in 7 bits, it will be. There's no difference from a pure ASCII string and a UTF-8 string containing those characters.
- If the character needs up to 11 bits, it will be spread across 2 bytes with padding.
- The padding indicates that this is one codepoint spread across two characters, not 2 1-byte codepoints.
- Take á. It corresponds to 225. Or '00011100001' in binary.
- With padding this becomes the 2 bytes '110 00011' and '10 100001'.
- Unicode aware systems will render these two bytes as as á.
- Unaware systems will interpret each byte as a separate codepoint and print ��.
For codepoints that need 12-16 bits will be spread across 3 bytes. And codepoints 17-21 bits will be spread across 4 bytes.